QUOTES STREAMER
We run one of the largest real-time, high-frequency, low-latency streaming systems in the world with over 3 million messages per second and over 1320 billion messages per month. We call these Quotes Streamers.
This article talks about the evolution of this mammoth system and the design considerations behind it.
The Need
In 2016, we had built our Quotes Streamer using Node and scaled up to 120K messages/sec with great difficulty. In March 2017, with our entry into equities markets, we were faced with a need to scale to 10 million messages per second. Our Node solution simply would not scale. There was absolutely nothing out there that we could leverage. And the technologies we were familiar with (Ruby, Node.js, Python, Java) just couldn’t do the job. We had to design and build it from scratch. That’s when we explored Erlang, Elixir and Golang, and decided to dive into the unknown realms of Golang to solve this massive problem.
The History
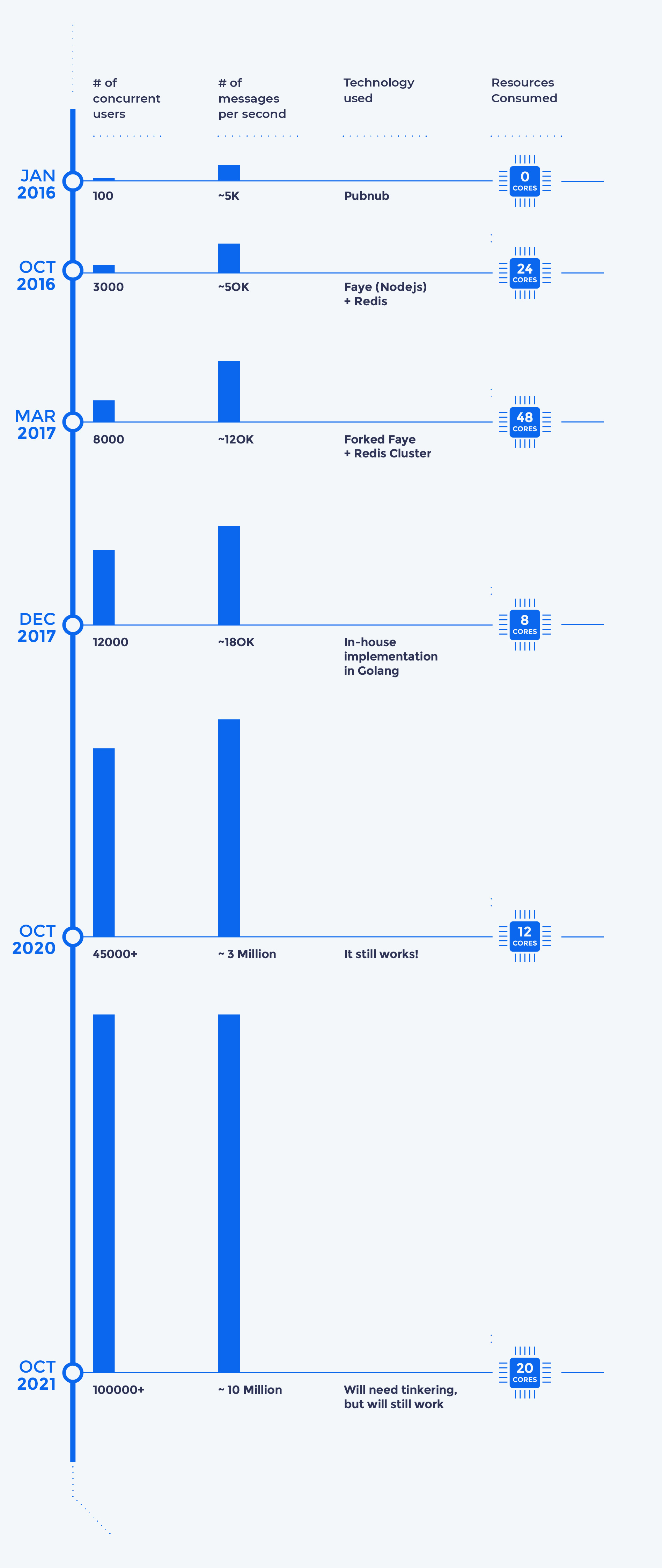
So how did we go from 5K to 120K and then design for 10M?
For the first beta launch in Jan 2016, we decided to test the waters with a hosted solution. Pubnub was the best option at the time. But with the sheer volume of messages, Pubnub would have cost us millions of dollars had we continued. :) Within a month, we began exploring open source solutions.
We had 1 developer, who was also our founder and CEO. Building from scratch wasn’t going to be easy. We explored every possible alternative, and by the end of the year, Faye won out for it’s simplicity and lightweight Bayeux protocol.
After 10 months with Faye, though, we were struggling again. Redis has a limit of 150k ops/second. The way Faye used Redis was causing it to cross this limit very often, forcing frequent restarts. That’s when we decided to fork Faye and use a better implementation for Redis, and even extended it to make use of a Redis cluster for horizontal scaling.
Barely 6 months in, and this approach started failing as well. Resource consumption was huge and horizontal scaling was not feasible beyond a handful of machines. At this point, we decided to build it ourselves. We began our explorations with Erlang, Elixir and Golang. After a month of benchmarking for our use-case, we chose Golang over Erlang and Elixir (see reason below in design section).
By the end of 2017 we saw that this had worked wonders for us. It helped us scale horizontally with utmost ease and, with very little tinkering, went from 180K to 3M over the next 2 years.
It's the end of 2020. This still works, and we are confident it will easily scale in 2021 to 10M+ and beyond.

The Design
Fire and forget
In our case, everything is updating every few milliseconds. Anything that’s a few seconds old is literally worthless. That’s why we choose to design it without any kind of storage or caching. This important consideration tremendously improved the scalability.
Since we had faced issues in the past with Redis, we decided to completely eliminate any use of memory, except process memory which is minimized as well.
Maintaining order
Every message is actually a trade that gets executed, and the latest message is the last traded price. You can’t possibly mess up the order.
Now, the initial thought was to maintain the ordering on the server. However, any mechanism to maintain order or state in a highly concurrent system, tends to pose bottlenecks at scale. Instead, we choose to do the ordering on the client side. Every message has a timestamp and the client simply discards any older message.
In classic Market Pulse fashion, we figured out a very simple solution that works well for us, and is one of the key reasons why the Quotes Streamer is so freakishly fast.
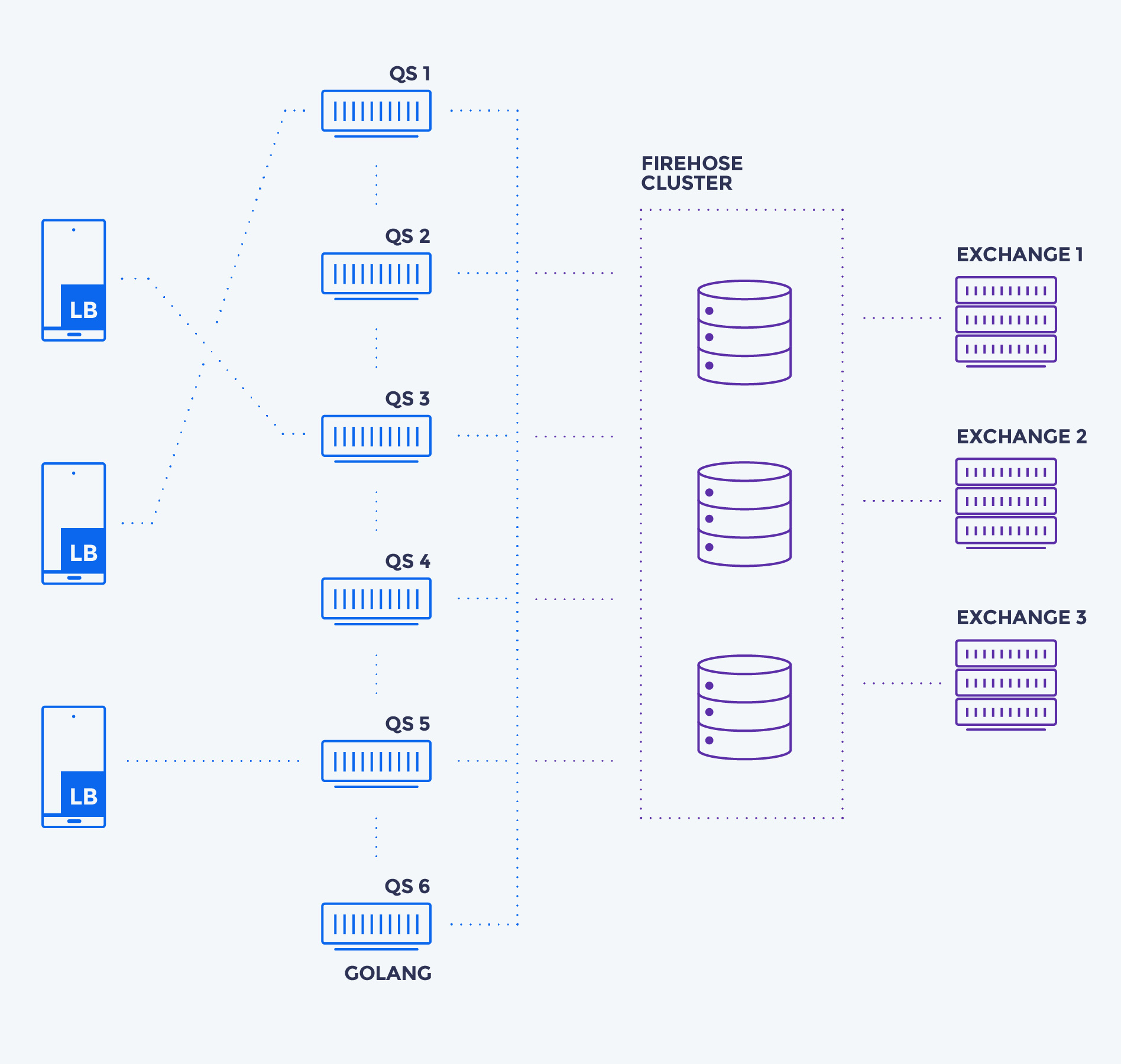
No DNS or Load Balancers
We decided to put the LB on the client. We don’t use DNS or LBs on server side at Market Pulse (another post on this soon). Our
ADN
serves the list of available servers to the client, which load balances, using a simple round robin algorithm.
We don’t just rely on the server being up or a simple heartbeat mechanism, because there is always a possibility of disconnection from upstream firehose. Our health check on the client ensures that it’s actually getting the messages it desires.
Shared-nothing architecture
We wanted to make sure we could scale to 100s of servers with no effort at all. For this, we ensured each instance was fully independent, unaware of other instances with nothing in common.
Everything is in process memory
In our design, we ensured we keep nothing on storage or in any in-memory cache. Everything is stored in process memory. You might say that a process could always die. And you’d be right. But we simply designed our system to be fault-tolerant. If a process dies, it is recreated. Yes, the subscriber data, past history of messages is lost. But that’s okay. The clients reconnect to another healthy server in the meantime, within 3 seconds. And this new process is just treated as a new addition to the cluster. There is no past history of messages, no list of subscribers to be restored from the older one.
Golang
We are very fond of Elixir. It could also work decently well for this purpose, but in our benchmarking, it really couldn’t beat the performance of Golang for this special use-case. Had we needed a distributed pub-sub or channels, Elixir would have been a much nicer fit. But, given that we used a shared-nothing architecture, Golang was ideal for the need at hand.
The Future
We are looking forward to open-sourcing the solution. If you would like to contribute, drop us a line here.
LOOKING TO WORK IN A PLACE WHERE YOU COME FIRST?
JOIN US